
Robots.txt
Your website is a bustling hub of information, but not all corners of your website are meant for every visitor or, more specifically, search engine robots. The Robots.txt file is a gentle but firm doorman, guiding these bots on where they can and can't go.
What is Robots.txt?
Imagine your website as a grand mansion with numerous rooms. The Robots.txt is like the guidelines given to guests on which rooms they can visit and which they should avoid. In digital terms, this file tells search engine robots which pages or sections of your site they should not index.
A sample of the Robots.txt file looks like the below:
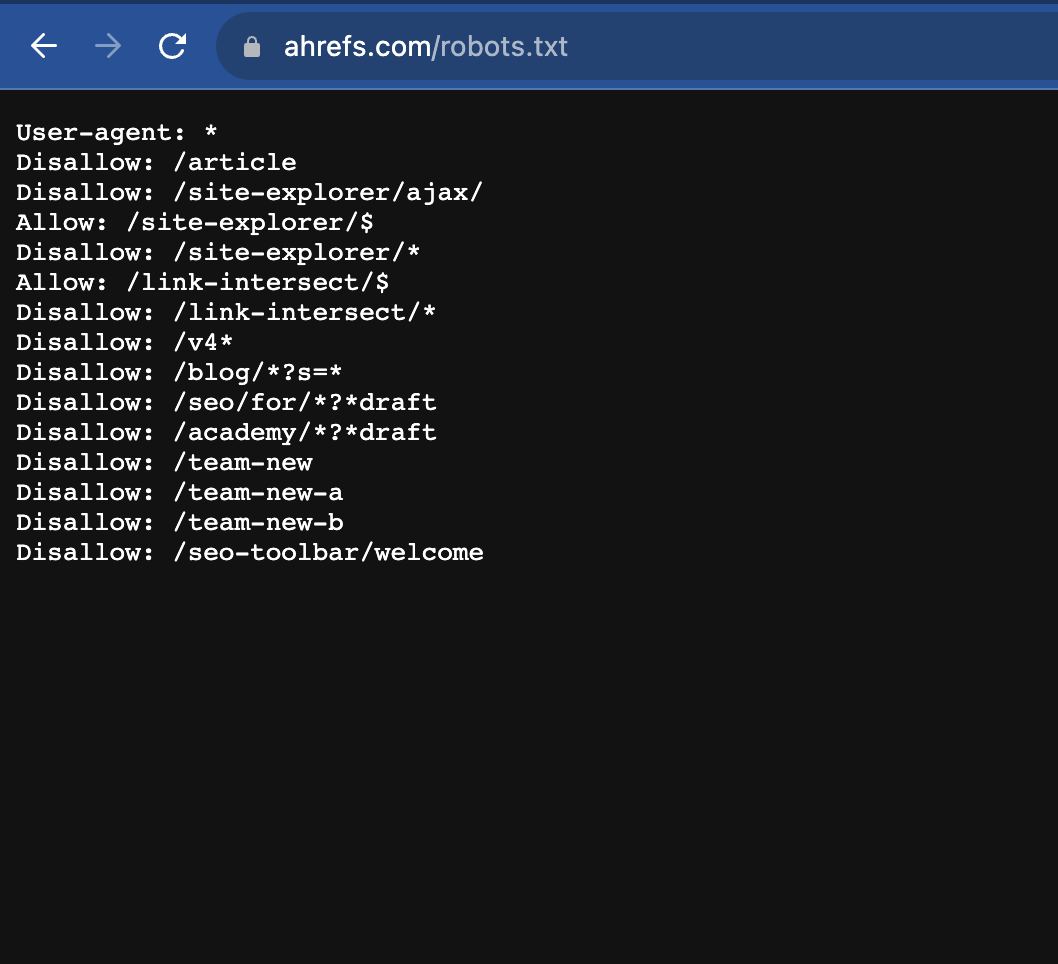
How Robots.txt Works:
When a search engine robot tries to visit a page on your site, it checks for the Robots.txt file first. This file provides instructions, allowing or disallowing the robot from accessing certain parts. If the file or the specific directive doesn't exist, the robot assumes it's free to explore everywhere.
Why is Robots.txt Important?
Precise Control Over Crawlers:
The primary advantage of Robots.txt is the control it offers. By deploying a well-crafted Robots.txt file, you can instruct search engines about which parts of your site should remain inaccessible, ensuring that sensitive, irrelevant, or non-public pages remain out of the public search domain.
Example: Imagine having a website with a public storefront and a private admin dashboard. Using Robots.txt allows search engines to access and index the storefront while keeping the dashboard confidential.
Efficient Resource Allocation:
While essential for indexing, web crawlers consume server resources every time they access your website. By directing these crawlers away from irrelevant or less important pages, you conserve server resources, ensuring a smoother experience for your visitors.
Avoidance of Duplicate Content:
Duplicate content can confuse search engines and may impact your SEO negatively. With Robots.txt, you can guide search engines to focus on the original or most relevant content, steering clear of redundant or duplicate pages.
Optimize Crawl Budget:
The term "crawl budget" refers to the number of pages a search engine will crawl on your website within a specific timeframe. If you've got a sprawling website with thousands of pages, it's essential to ensure that search engines focus on the most valuable pages. Using Robots.txt, you can help guide Googlebot and other search engine crawlers to allocate their crawl budget more effectively, ensuring priority pages get indexed.
Protection of Non-Public and Duplicate Pages:
Not all web pages are created for public viewing. Some, like admin logins, internal search results, staging sites, or even certain landing pages, might be better left out of search engine results. Thankfully, with Robots.txt, you can specify these preferences, ensuring only the most relevant pages appear in search results.
Safeguarding Vital Resources:
Sometimes, resources like PDFs, proprietary images, or exclusive videos might be intended for something other than broad public distribution. Robots.txt can help ensure such resources aren't indexed, keeping them exclusive to your website's visitors.
Setting Up Robots.txt :
- Create a Text File: Create a new text file named "Robots.txt".
- Instructions: Add your rules, specifying the user agent (like Googlebot) and the pages you want to disallow or allow.
- Place in Root Directory: Ensure the Robots.txt file is in the root directory of your website (e.g., https://www.yourwebsite.com/Robots.txt).
Example:

In this example, all robots (denoted by *) are instructed not to access anything in the "private" and "test" directories of the website.
Understanding Robots.txt Syntax
The Robots.txt syntax is straightforward. At its core, it consists of directives instructing search engines on what to do when they encounter specified paths on your site. Each directive has a specific purpose, and combining them effectively helps optimize your site's visibility and accessibility.
User-agent:
This specifies the search engine robot to which the rule applies. If you want the rule to apply to all robots, use an asterisk (*).
Example:

Disallow:
Used to instruct search engine robots not to crawl or index specific pages or directories.
To block a specific folder:

To block a specific webpage:
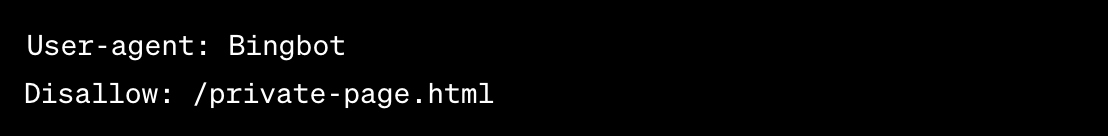
Allow (used mainly by Google):
This is the opposite of Disallow. Search engine robots can access a page or folder, even inside a disallowed directory.
Allow: /private/public-page.htmlSitemap:
You can point search engines to your XML sitemap using this directive. This helps search engines discover all crawlable URLs.
Example:

Crawl-delay:
This instructs robots to wait a specified number of seconds between successive crawls, reducing the load on the server. Note: Not all search engines respect this directive.
Crawl-delay: 10Example:
To instruct a robot to wait 10 seconds between requests:

Using the above directives effectively, website administrators can guide search engine robots in navigating their sites. By understanding and applying these directives, you can optimize your site's visibility in search engines while keeping private content hidden. Always test your Robots.txt file to ensure it works as intended.
Do's and Don'ts For Robots.txt
✅ Do's:- Be Clear: Ensure instructions are clear to prevent essential pages from being excluded from search engines.
- Update: If your site evolves, update the Robots.txt to reflect these changes.
- Over-Exclude: Be cautious not to block important pages or directories that you want to be indexed.
- Rely Solely for Privacy: If you want to keep pages completely private, use other methods alongside, like password protection.
Conclusion
Think of Robots.txt as the first point of interaction between your website and search engine robots. It's not just about exclusion but intelligent guidance to ensure your site appears in searches the way you desire. By mastering the usage of this simple file, you can significantly improve your website's relationship with search engines and, by extension, with your potential audience.
FAQs
User-agent: *
Disallow: /